Overview
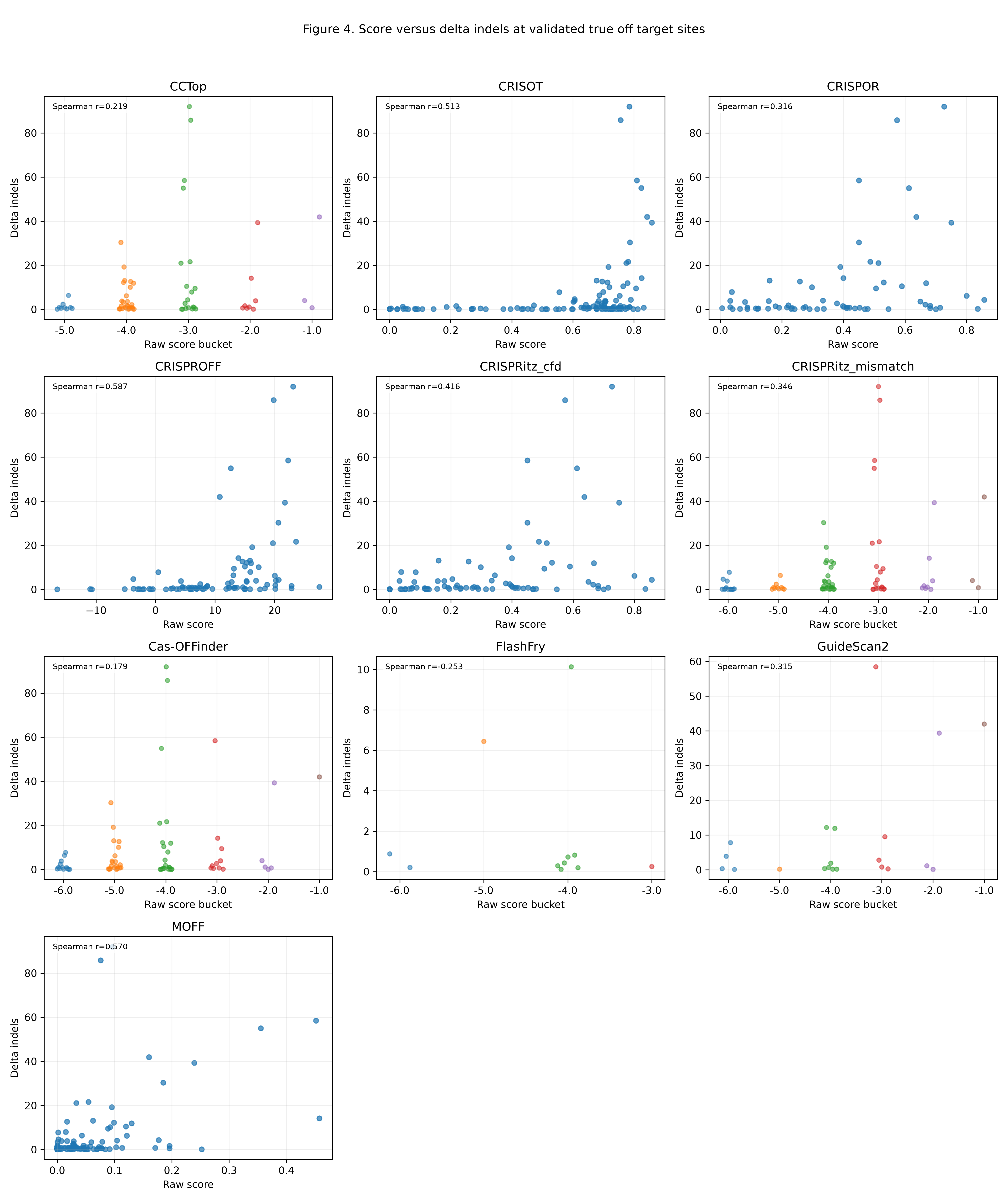
Figure 4 compares tool score with observed editing signal at validated true off target sites.
Truth labels and score classes
Code
DISCRETE_TOOLS = {'Cas-OFFinder', 'GuideScan2', 'CCTop', 'FlashFry', 'CRISPRitz_mismatch'}
def normalize_truth_status(value):
if pd.isna(value):
return 'unknown'
if isinstance(value, (bool, np.bool_)):
return 'true' if bool(value) else 'false'
text = str(value).strip().lower()
if text in {'true', 'off'}:
return 'true'
if text in {'false', 'on'}:
return 'false'
return 'unknown'
figure4_df = matched_long.copy()
figure4_df['truth_status'] = figure4_df['truth_status'].map(normalize_truth_status)
figure4_df['is_self_match'] = (
figure4_df['guide_key'].astype('string').eq(figure4_df['offtarget_seq'].astype('string'))
& figure4_df['guide_key'].notna()
& figure4_df['offtarget_seq'].notna()
)
figure4_df['score_class'] = figure4_df['tool'].astype(str).map(
lambda tool: 'coarse_ordinal' if tool in DISCRETE_TOOLS else 'continuous_site_level'
)
figure4_df[['tool', 'truth_status', 'raw_score', 'delta_indels', 'score_class']].head(10)
| 0 |
Cas-OFFinder |
true |
-2.0 |
4.08 |
coarse_ordinal |
| 1 |
Cas-OFFinder |
true |
-4.0 |
21.05 |
coarse_ordinal |
| 2 |
Cas-OFFinder |
false |
-5.0 |
0.00 |
coarse_ordinal |
| 3 |
Cas-OFFinder |
false |
-5.0 |
0.00 |
coarse_ordinal |
| 4 |
Cas-OFFinder |
false |
-5.0 |
0.00 |
coarse_ordinal |
| 5 |
Cas-OFFinder |
false |
-5.0 |
-0.02 |
coarse_ordinal |
| 6 |
Cas-OFFinder |
false |
-6.0 |
0.00 |
coarse_ordinal |
| 7 |
Cas-OFFinder |
false |
-6.0 |
0.00 |
coarse_ordinal |
| 8 |
Cas-OFFinder |
false |
-5.0 |
-0.06 |
coarse_ordinal |
| 9 |
Cas-OFFinder |
true |
-4.0 |
0.10 |
coarse_ordinal |
The notebook distinguishes continuous score scales from coarse ordinal score scales before plotting.
Filtered matched rows
Code
figure4_df = figure4_df[
(figure4_df['truth_status'] == 'true')
& (~figure4_df['is_self_match'])
& figure4_df['delta_indels'].notna()
& figure4_df['raw_score'].notna()
].copy()
figure4_df[['tool', 'guide_key', 'delta_indels', 'raw_score', 'score_class']].head(10)
| 0 |
Cas-OFFinder |
AAAGAACATCCAAGGCTGAGCGG |
4.080 |
-2.0 |
coarse_ordinal |
| 1 |
Cas-OFFinder |
AAAGAACATCCAAGGCTGAGCGG |
21.050 |
-4.0 |
coarse_ordinal |
| 9 |
Cas-OFFinder |
ACTTTGCTGCCACAATACCTTGG |
0.100 |
-4.0 |
coarse_ordinal |
| 14 |
Cas-OFFinder |
ACTTTGCTGCCACAATACCTTGG |
0.143 |
-4.0 |
coarse_ordinal |
| 32 |
Cas-OFFinder |
ATAGGAGAAGATGATGTATAGGG |
0.736 |
-3.0 |
coarse_ordinal |
| 38 |
Cas-OFFinder |
ATAGGAGAAGATGATGTATAGGG |
0.266 |
-5.0 |
coarse_ordinal |
| 45 |
Cas-OFFinder |
ATAGGAGAAGATGATGTATAGGG |
0.182 |
-5.0 |
coarse_ordinal |
| 57 |
Cas-OFFinder |
CATACAGGGCTCTGTACCCAGGG |
0.292 |
-5.0 |
coarse_ordinal |
| 62 |
Cas-OFFinder |
CCCTGGCTACCTCCCCTACCCGG |
1.704 |
-3.0 |
coarse_ordinal |
| 63 |
Cas-OFFinder |
CCCTGGCTACCTCCCCTACCCGG |
0.547 |
-3.0 |
coarse_ordinal |
Rows are restricted to validated true off target sites with numeric score and numeric delta_indels. Self matches are removed.
Correlation helper
Code
def spearman_no_scipy(x: pd.Series, y: pd.Series) -> float:
paired = pd.DataFrame({'x': pd.to_numeric(x, errors='coerce'), 'y': pd.to_numeric(y, errors='coerce')}).dropna()
if len(paired) < 2 or paired['x'].nunique() < 2 or paired['y'].nunique() < 2:
return np.nan
xr = paired['x'].rank(method='average')
yr = paired['y'].rank(method='average')
return float(xr.corr(yr, method='pearson'))
The figure annotates each panel with a Spearman correlation computed directly from the plotted values.