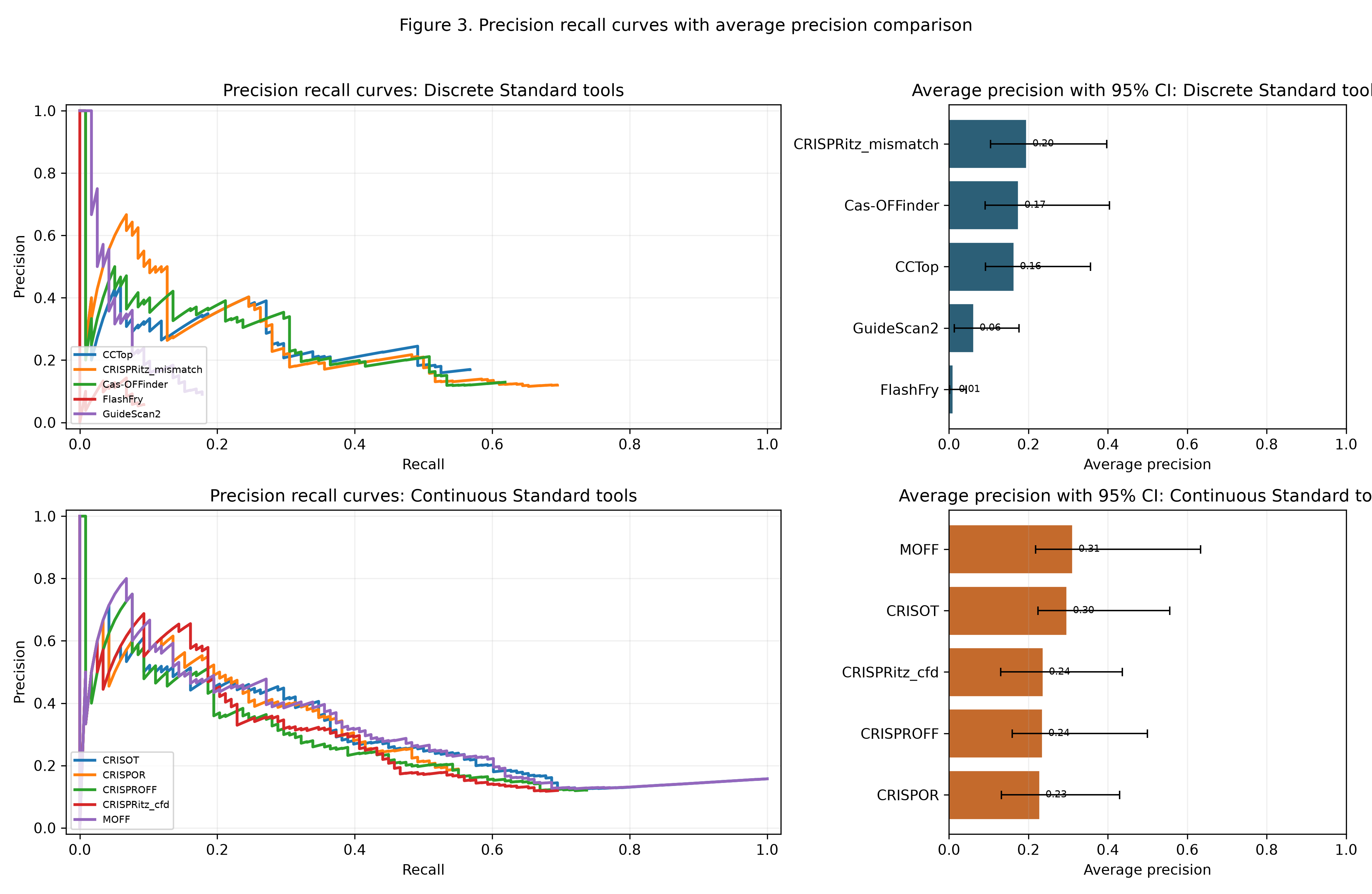
Figure 3 summarizes ranking performance across tools. The left panels show the precision recall curves. The right panels show average precision with guide bootstrap intervals.
The stored summary already contains the global average precision value for each tool. The remaining steps add guide bootstrap intervals and prepare the plotted tables.
Bootstrap helper functions
Code
DISCRETE_TOOLS = {'Cas-OFFinder', 'GuideScan2', 'CCTop', 'FlashFry', 'CRISPRitz_mismatch'}def normalize_truth_status(value):if pd.isna(value):return'unknown'ifisinstance(value, (bool, np.bool_)):return'true'ifbool(value) else'false' text =str(value).strip().lower()if text in {'true', 'off'}:return'true'if text in {'false', 'on'}:return'false'return'unknown'def average_precision_from_ranked_rows(rows: pd.DataFrame, n_true_sites: int) ->float:if n_true_sites <=0:return np.nan ranked = rows.dropna(subset=['rank']).sort_values(['rank', 'match_key']).reset_index(drop=True)if ranked.empty:return0.0 is_true = ranked['truth_status'].map(normalize_truth_status).eq('true').to_numpy()ifnot is_true.any():return0.0 precision = np.cumsum(is_true) / np.arange(1, len(is_true) +1)returnfloat(precision[is_true].sum() / n_true_sites)
normalize_truth_status standardizes the truth labels used in the matched site table. average_precision_from_ranked_rows recalculates average precision from an already ranked set of matched rows.
The bootstrap operates at guide level. The matched site table therefore needs a numeric rank column and the guide table needs a numeric count of validated true sites.
Each bootstrap replicate resamples guides, reconstructs the matched rows for that sample, and recalculates average precision. The resulting interval reflects variation across guide composition.